


기술로 배움을 연결합니다
이 공간은 CT의 Edutech Research팀에서 연구하고 있는 주제를 공유하는 장입니다.
내용은 모두에게 공유되어 있으나 내용 중 일부는 저작권의 보호를 받을 수 있으므로, 공유 시 반드시 출처를 밝혀주시기 바랍니다.
Math Word Problem (MWP) solving involves understanding mathematical questions expressed in natural language and deriving the appropriate mathematical equations. Traditional approaches heavily rely on simple lexical pattern matching, limiting their flexibility in diverse real-world scenarios. Our co-authored paper introduces ATHENA (Attention-based THought Expansion Network Architecture), designed to mimic human cognitive processes for more generalized and robust mathematical reasoning.
Let's explore how ATHENA achieves robust performance and why this matters for mathematical reasoning in AI.
Research Background
Math word problem (MWP) solving involves translating complex linguistic descriptions into mathematical expressions. Traditional models tend to memorize lexical patterns rather than understand mathematical principles and procedures, limiting their ability to generalize to unseen or slightly varied problems.
Consider the following cases: calculating the area of a rectangle and determining how many items can be evenly distributed across containers. While both require multiplication, they involve different types of conceptual understanding.
Previous methods have struggled with two key aspects in reaching human-level understanding:
•
Conceptual knowledge: Understanding how mathematical principles apply in various contexts.
•
Procedural knowledge: The ability to deduce answers step by step through logical reasoning.
ATHENA is specifically designed to bridge this gap, enabling the model to expand its reasoning capabilities by mimicking human cognitive processes.
Methodology: ATHENA

ATHENA: Mathematical Reasoning with Thought Expansion
NLP
Math Word Problem
ML

Language models (LMs) have become remarkably proficient in natural language reasoning tasks by leveraging the rationales they generate to enhance their reasoning capabilities. These rationales serve a dual purpose: they not only help improve reasoning performance but also justify model decisions. The problem? Perfect rationales are often impossible to obtain.
Our research, How Ambiguous Are the Rationales for Natural Language Reasoning? A Simple Approach to Handling Rationale Uncertainty, explores this issue in depth. The study introduces AURA (Ambiguous Rationale Utilization for Robust Answering), a novel two-stage reasoning framework that enhances model robustness in the face of ambiguous rationales. Let’s dive into the details of this study and its implications for natural language reasoning.
Research Background and Problem Statement
Language models (LMs) have achieved significant progress in solving complex reasoning tasks that require commonsense knowledge, as well as in handling challenging multiple-choice questions. In particular, recent advancements have enabled models to leverage generated rationales to further enhance reasoning performance. Nevertheless, obtaining perfect rationales from models (or even from humans) is practically impossible. While human annotation can improve the quality of rationales, it is extremely costly and does not guarantee perfect conditions.
More importantly, learning the patterns of rationales, which are generated based on an enormous number of different statements, is nearly impossible. This is because rationales inherently contain various normative concepts, which justify different ways of thinking or acting—in other words, the same question may have different explanations. As a result, this diversity causes models to experience uncertainty, making it challenging to learn rationales effectively.
Handling Ambiguous Rationales in Natural Language Reasoning
Natural Language Reasoning
NLP
ML
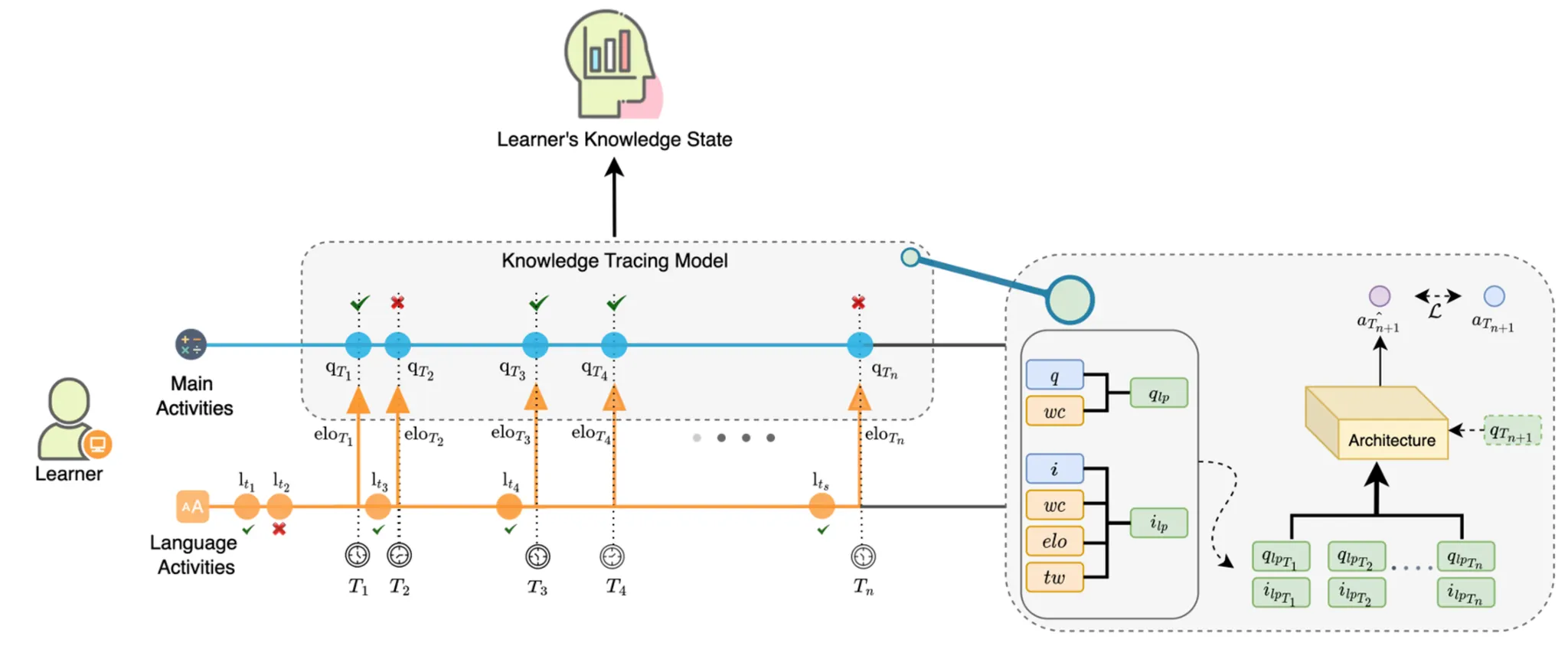

Abstract. With an increasing interest in personalized learning, active research is being conducted on knowledge tracing to predict the learner’s knowledge state. Recently, studies have attempted to improve the performance of the knowledge tracing model by incorporating various types of side information. We propose a knowledge tracing method that utilizes the learner’s language proficiency as side information. Language proficiency is a key component of comprehending a question’s text and is known to be closely related to students’ academic performance. In this study, language proficiency was defined with Elo rating score and time window features, and was used in the knowledge tracing task. The dataset used in this study contains 54,470 students and 7,619,040 interactions, which were collected from a real-world online-learning platform. We conducted a correlation analysis to determine whether the language proficiency information of students was related to their ability to solve math word problems. In addition, we examined the effect of incorporating the language proficiency information on the knowledge tracing models using various baseline models. The analysis revealed a high correlation between the length of word problems and students’ language proficiency. Furthermore, in experiments with various baseline models, utilizing the language proficiency information improved the knowledge tracing model’s performance. Finally, when language proficiency information was incorporated, the cold start problem of the knowledge tracing model was mitigated. The findings of this study can be used as a supplement for educational instruction.
Language Proficiency Enhanced Knowledge Tracing
Knowledge Tracing
Student Modeling
Learning Analytics
Language Proficiency

Data matters. Accordingly, data augmentation has been an important ingredient for boosting performances of learned models. Prior data augmentation methods for few-shot text classification have led to great performance boosts. However, they have not been designed to capture the intricate compositional structure of natural language. As a result, they fail to generate samples with plausible and diverse sentence structures. Motivated by this, we present the data augmentation using lexicalized probabilistic context-free grammars that generates augmented samples with diverse syntactic structures with plausible grammar.

Learning with Limited Data using Compositionality in Language
NLP
ML
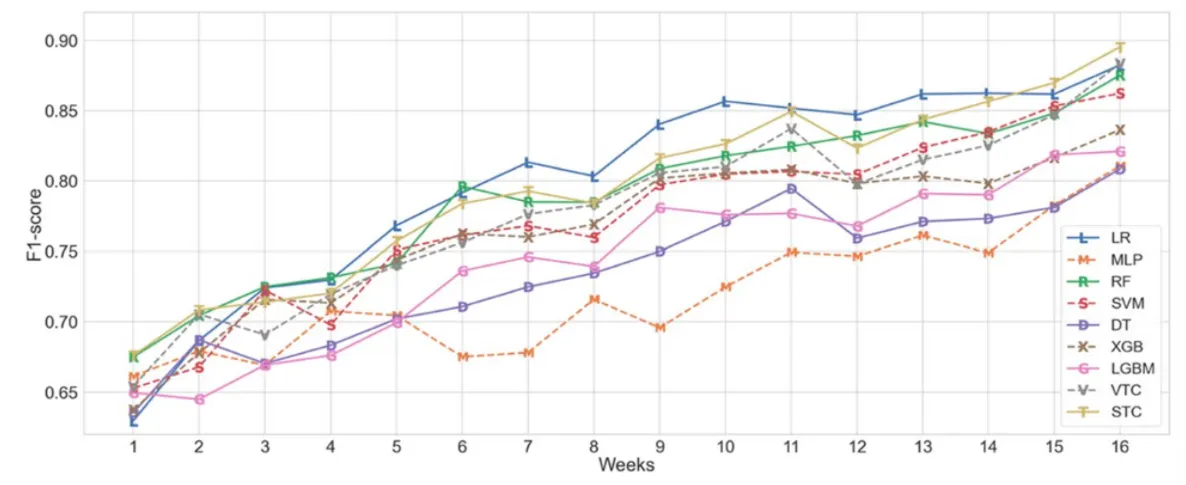
오늘은 교육 전문가들의 의견을 반영하여, 실용적으로 실제 교육 현장에서 활용하기 용이한 학습 성취 예측 방법을 제안한 연구를 소개하도록 하겠습니다.
학습 성취 예측에 대한 선행 연구들
학생의 학습 성취를 미리 예측할 수 있다면, 적절한 교육적인 조치를 취함으로써 학습의 효과를 높이는 데 기여할 수 있습니다. 이러한 기대 하에 학생의 학습 성취를 예측하기 위한 연구들이 오랜 시간 꾸준히 진행되어 왔습니다. 학습자 해당 분야에 대한 선행 연구들을 분석하면 다음과 같은 특징을 발견할 수 있습니다.
교육 현장의 목소리를 반영한 LMS 데이터 기반의 실용적인 학습 성취 조기 예측 방법 제안
LMS
Education
Personality detection identifies a person's characteristic patterns in the online text he or she creates. Active participants on social media yield a considerable amount of online posts implying their psychological status. Having emerged personalized systems using online postings, natural language processing tasks requires psycholinguistic knowledge to detect individuals' personality traits. This emerging task is currently in demand for extensive application scenarios such as personalized recommendation systems, dialogue systems, and more.
Yet prior personality detection has been under-explored and restricted. Existing methods require resource-intensive and time-consuming professional tags to infer personality traits using ground-truth information. Those using deep neural networks have still focused on extra resources of lexical features in addition to the labeled training data. The performance heavily relying on such manual resources as Linguistic Inquiry and Word Count (LIWC) and Medical Research Council (MRC) restricts the pre-trained model's psycholinguistic proficiency and constrains the method in words only specified in the dictionaries. Not only utilizing the dictionaries but pre-trained language models are not in proper use.
Emerging Knowledge from Pre-Trained Language Models for Psycholinguistic Analysis
Psycholinguistic Analysis
NLP
ML
ⓒ CT Corp. 2026